- 👋 Hey there! I'm Evgenii./
- Posts/
- Measuring Context Switching and Memory Overheads for Linux Threads: A Deep Dive into NPTL Performance/
Measuring Context Switching and Memory Overheads for Linux Threads: A Deep Dive into NPTL Performance
Table of Contents
When designing high-load concurrent servers, the age-old question always comes up: “How expensive are threads, really?” After years of working with concurrent systems at Semrush and various startups, I’ve heard all the claims - “context switches will kill your performance!” or “thousands of threads will exhaust your RAM!” But are these concerns still valid in 2023?
Let me be clear upfront: this isn’t about picking sides in the threads vs. event-driven debate. Both are tools with their place. What I want to do is measure the actual costs, with real numbers and code you can run yourself.
The Evolution: Linux Threads and NPTL #
Remember the dark ages before Linux 2.6? Threads were basically hacked on top of processes. No futexes, no efficient synchronization (they used signals!), and multi-core support was… let’s say “suboptimal.”
Then came NPTL (Native POSIX Thread Library) in 2005, proposed by Ulrich Drepper and Ingo Molnar from Red Hat. If you haven’t read the design paper, I highly recommend it - it’s a masterclass in systems design. NPTL brought:
- 7x faster thread creation
- Much faster synchronization via futexes
- Proper multi-core utilization
- Integration with the O(1) scheduler
Even today, 18 years later, you’ll see nptl in glibc paths - a testament to its lasting impact.
What Happens During a Context Switch? #
Context switching has two key aspects in the Linux kernel:
- When the switch happens (scheduler decision)
- How it happens (the actual mechanism)
Here’s the sequence when switching from thread A to thread B:
- Mode switch: Jump to kernel mode via system call or timer interrupt
- Save state: Store thread A’s registers
- Scheduler: Decide which thread runs next
- Memory management: Load thread B’s page tables
- Restore state: Load thread B’s registers
- Return: Jump back to user space
But how long does all this take?
Measuring Context Switch Overhead #
I’ve built benchmarks using two techniques to trigger deliberate context switches:
- Pipe ping-pong: Two threads alternately read/write to a pipe, forcing switches
- Condition variable signaling: Threads signal each other through pthread conditions

Here’s what I measured on my test machine (Haswell i7-4771):
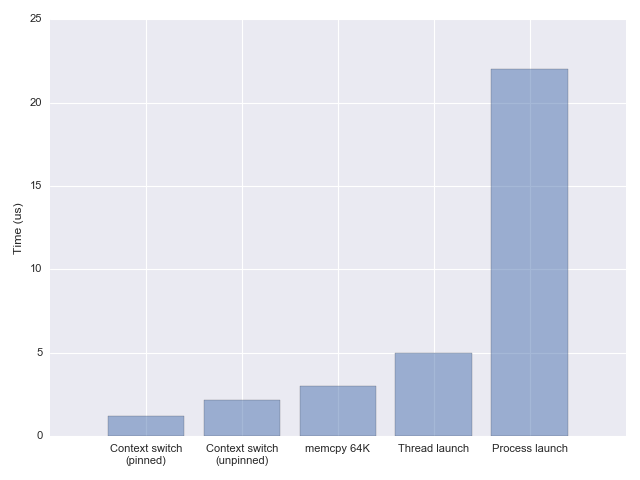
- With CPU pinning (single core): 1.3-1.6 microseconds per switch
- Without pinning (allows migration): ~2.3 microseconds per switch
These numbers represent the direct cost only. The indirect cost - cache invalidation when switching working sets - is harder to measure but often more significant. Google’s excellent talk on fibers covers this in detail.
Practical Performance Impact #
Is 1-2 microseconds significant? For perspective, copying 64 KiB of memory takes about 3.2 microseconds on the same machine. So a context switch is faster than a modest memcpy.
Here’s a more realistic benchmark - echoing messages through pipes between threads:
|
|
Results: ~385,000 iterations per second when pinned to a single core. This makes sense - each iteration has two context switches at 1.3 µs each = 2.6 µs per iteration.
For comparison, I rewrote this in Go using goroutines and channels:
|
|
The Go version achieves ~2.75 million iterations per second - about 7x faster. Why? Goroutine switches don’t require kernel context switches. Google’s fibers achieve similar performance using a new Linux system call.
Memory Usage: Virtual vs. Resident #
Now let’s tackle the other concern: memory overhead. Each thread needs its own stack, typically 8 MiB on Linux:
|
|
When I launch 10,000 threads, htop shows 80 GiB of virtual memory but only 80 MiB of resident memory. How is this possible on a 16 GiB machine?
Understanding Virtual Memory #
Linux uses lazy allocation. When you malloc memory, it doesn’t actually exist until you touch it. Here’s a demonstration:
|
|
Output:
started: max RSS = 4780 kB; vm size = 6524 kB
after malloc: max RSS = 4780 kB; vm size = 416128 kB
after touch: max RSS = 410916 kB; vm size = 416128 kB
Notice how virtual memory jumps immediately after malloc, but resident memory only increases after we touch it.
Managing Thread Stack Size #
You can control stack size programmatically:
|
|
But what’s the right size? Consider:
- Too small: Risk stack overflow in deep recursion
- Too large: Waste virtual address space (critical on 32-bit systems)
- Default 8 MiB: Usually fine for 64-bit systems with <10,000 threads
On 32-bit Linux (3 GiB address space), the 2 MiB default limits you to ~1,500 threads. On 64-bit systems, I can create ~32,000 threads before hitting OS limits.
Real-World Implications #
After years of optimizing concurrent systems, here’s my take:
The folklore from the early 2000s is outdated. On modern Linux with NPTL:
- Context switches are fast (1-2 µs)
- 10,000 threads are perfectly manageable
- Memory is rarely the limiting factor on 64-bit systems
At Semrush, we’ve successfully run services with thousands of threads in production. The key insights:
- Context switch cost is usually negligible compared to actual work (parsing, I/O, business logic)
- Virtual memory != physical memory - don’t panic at large VIRT numbers
- Choose the model that fits your problem - threads for simplicity, async for extreme concurrency
Google runs an order of magnitude more threads by tuning the kernel and reducing default stack sizes. But for most applications, 10,000 concurrent threads provide plenty of headroom with a much simpler programming model - no callback hell, straightforward debugging, natural code flow.
Benchmarking Yourself #
Want to verify these numbers on your hardware? I’ve published all the benchmarks:
|
|
Remember to:
- Use
tasksetto pin to specific cores - Run multiple times and average results
- Test with your actual workload patterns
Conclusion #
Linux threading has come a long way since NPTL. In 2023, the performance characteristics are:
- Context switches: 1.3-1.6 µs (direct cost)
- Thread creation: ~10 µs (see my other benchmarks)
- Memory: 8 MiB virtual (mostly uncommitted) per thread
- Practical limit: 10,000-30,000 threads depending on configuration
The bottom line? For many applications, threads provide sufficient concurrency with a simpler programming model. Yes, goroutines and async/await can handle more concurrent tasks, but at the cost of complexity. Choose based on your actual requirements, not outdated folklore.
Modern Linux can handle far more threads than most applications will ever need. Focus on your architecture and algorithms - the threading overhead is probably the least of your worries.
What’s your experience with high-concurrency systems? Have you hit thread limits in production? I’d love to hear about your use cases and optimizations.